
咨询热线:
0830-2509596
0830-2509596

,论文中放出了OpenAI家推理模型三兄弟在IOI和CodeForce上的具体成绩。
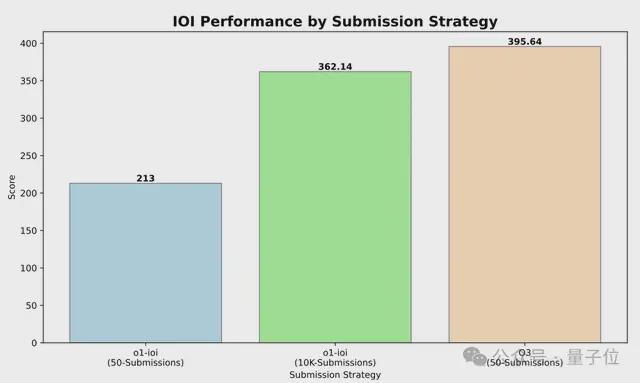
三兄弟分别是OpenAI o1、o1-ioi(以o1为基础微调等改进而来)、o3,三者成绩如下。
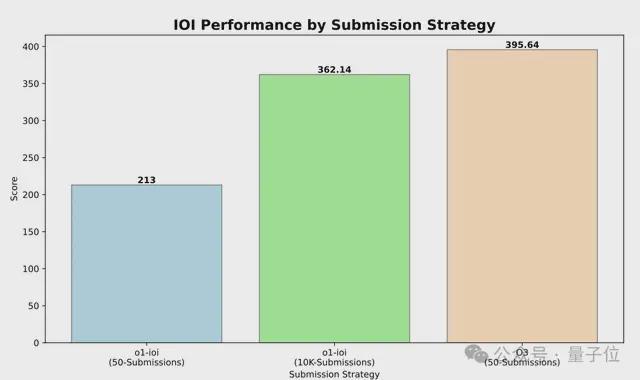
其中,o1-ioi和o3的评分显著高于o1,尤其是o3,已经接近顶级人类选手:
有网友注意到,o1-ioi在IOI 2024上表现出色,是因为它为每个问题生成了10000个候选解决方案,还用上了复杂的test-time策略;而o3在严格限制下达到顶级选手水平,仅用了50次提交,且无人工策略干预。
o3的表现,证明了通过大规模端到端RL(强化学习),无需依赖人工设计的测试时推理策略,就能自己学会先写暴力求解代码提高效率,再用其他方法交叉验证的策略。

下一个里程碑,是出现「单次提交就能搞定每个问题」的模型。或许OpenAI o4会带来这个时刻。
OpenAI表示,这篇论文的研究目的,是探究在复杂编码和推理任务中,RL对大模型所起到的作用。
研究过程还对比了通用推理模型与领域特定系统的性能,探索提升AI推理能力的有效路径。
通过RL训练,o1能生成CoT(chain-of-thought,思维链),其作用是思考和解决复杂问题,帮助模型识别和纠正错误,将复杂任务分解为可管理的部分,并在方法失败时探索替代解决方案路径。
相比非推理模型(如GPT-4o),和早期推理模型(如o1-preview),o1成绩均有显著提升。
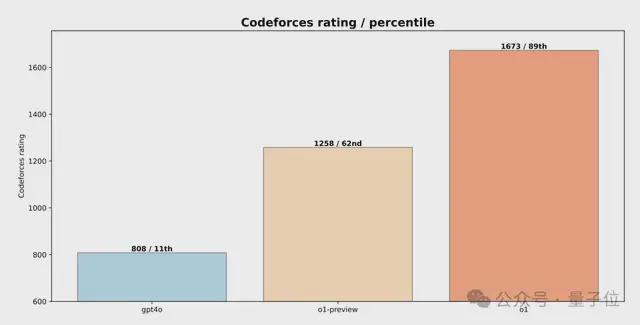
此外,研究人员在对o1进行开发和评估的过程中,发现增加「RL计算量」以及「test-time推理计算量」两方面的工作,都能持续提升模型性能。
如下图所示,扩展RL训练和扩展test-time推理均带来了显著的收益。
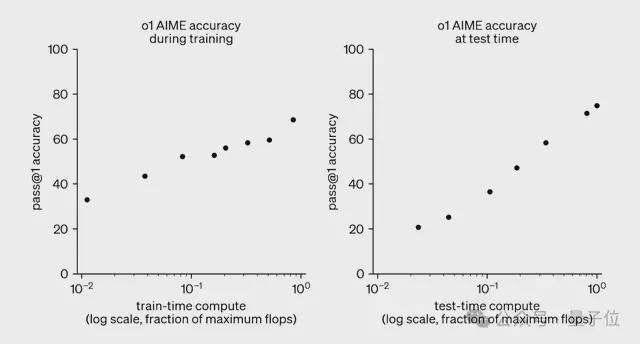
在发现增加「RL计算量」以及「test-time推理计算量」的重要性后,OpenAI团队在o1基础上进行针对性训练,得到o1-ioi,目标直指IOI 2024。
除了针对编码任务的持续RL训练外,o1-ioi还结合了专为竞赛编程而设计的专用test-time推理策略(类似AlphaCode的人工设计的test-time推理策略)。
通过将额外的训练计算专用于编程问题,团队增强了模型规划、实施和调试更多涉及的解决方案的能力。
该模型通过迭代运行和优化解决方案来改进其推理能力,从而增强了其编码和解决问题的能力。
它有10个小时的时间,来解决6个具有挑战性的算法问题,每个问题最多允许提交50次。
参赛期间,系统为每个问题生成了10000个候选解决方案,并使用test-time推理策略选了50个方案来提交——这里的test-time推理策略是,根据IOI公共测试用例、模型生成测试用例和学习的评分函数上的表现,来确定每个提交内容的优先级。
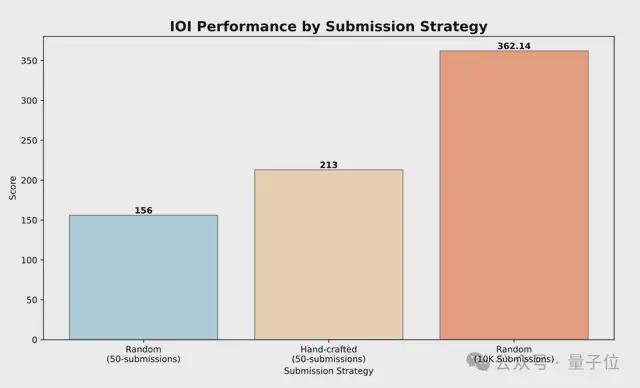
然后,团队用一个简单的筛选条件来拒绝任何未通过公开测试的解决方案时,评分上升到2092。
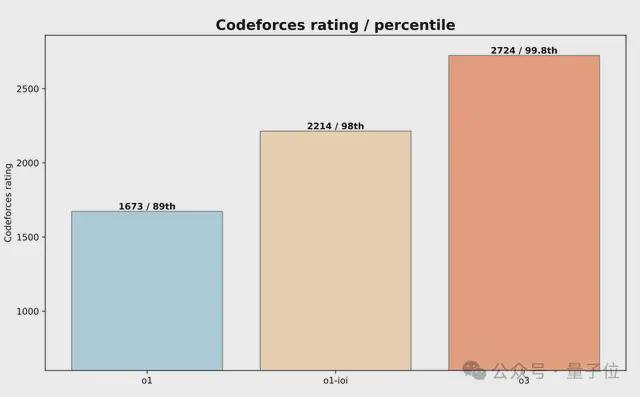
最终,在完整的test-time推理策略推动下,o1-ioi的评分飙升到2214。
这些结果证实,特定领域的RL微调与高级选择启发式相结合,可以显著提高有竞争力的编程结果。
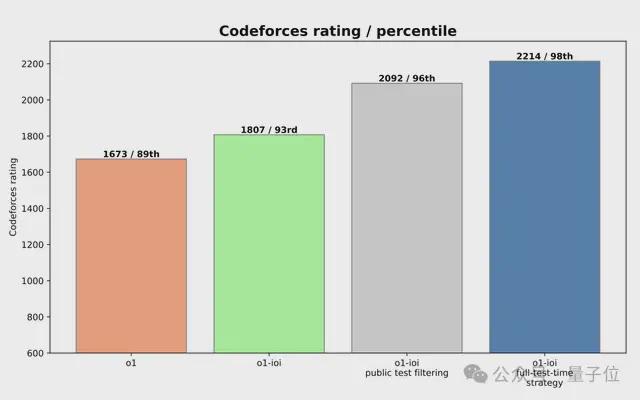
研究人员表示,o1-ioi的表现,证明特定领域的RL微调与先进选择策略,是可以提升竞技编程成绩的。
基于o1和o1-ioi的表现,OpenAI团队探索了纯RL训练、不依赖人工设计的test-time策略的局限性。
甚至试图探索用RL进一步训练,该模型是否能够自主开发和执行自己的test-time推理策略
为此,团队取得了o3的早期checkpoint的访问权限,来评估开云网站竞赛编程。
参与IOI 2024竞赛时,o3与o1-ioi一样严格遵守官方规则,每个问题最多允许提交50次。
与o1-ioi为每个子任务单独采样解决方案不同,团队在评估o3时,采用了不同的方法:
多提一句,参加IOI 2024的o3版本比参加CodeForce的o3版本更新,包含了额外的更新的训练数据。
在单个问题只能提交50次的限制下,o3在IOI 2024的最终得分是395.64,超过了IOI 2024金牌门槛。
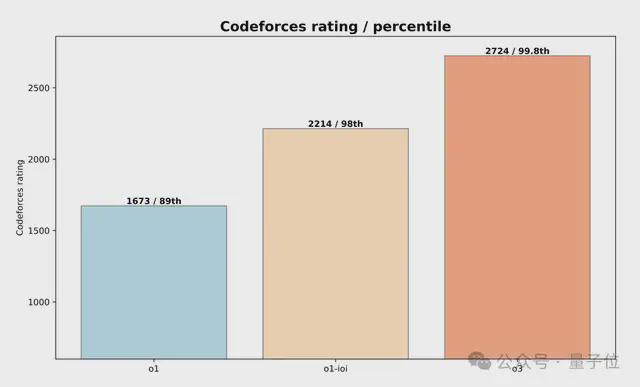
而在CodeForce基准测试上,仅仅依靠进一步的RL,o3就获得了2724分的成绩,力压99.8%的选手。
值得注意的是,从得分2214的o1-ioi(超越98%选手),到得分2724的o3(超越99.8%选手),反映了推理模型在竞赛编程中的显著提升。
这表明o3能够以更高的可靠性,解决更广泛的复杂算法问题,使其能力更接近CodeForces的顶级人类竞争对手。
更有意思的是,o3在CodeForce参赛期间展现出了更深思熟虑的思维链。
面对验证复杂的难题,o3在端到端RL期间,竟然学会了先写出暴力解法,再用最优算法的结果来交叉验Kaiyun官方入口证。
综上,团队表明,o3的性能优于o1-ioi的原因,不依赖于针对IOI的特定人工设计的test-time策略。
相反,o3训练期间出现的复杂test-time技术——如用暴力解法来验证输出——成为了人工设计策略的替代品,让o3不需要o1-ioi所需的手动设计聚类、选择pipeline等需求。
除了竞赛编程,论文还在真实的软件工程任务上测试了OpenAI推理模型三兄弟的表现。
三兄弟不仅能在竞赛编程中直逼人类顶尖选手,在真实的软件工程任务上也有亮眼表现。
HackerRank Astra由65个面向项目的编码挑战组成,每个挑战都是为了模拟真实的软件开发任务而精心设计的。
这些挑战涵盖了一系列框架,包括 React.js、Django 和 Node.js,允许获得构建功能和应用程序的实践经验。
该数据集的与众不同之处在于,它专注于评估反映实际开发环境的复杂、多文件、长上下文场景中的问题解决技能。
与典型的竞争性编程数据集不同,HackerRank Astra不提供公开的测试用例,这使OpenAI团队无法依赖人工制作的测试时策略。
使用此数据集评估性能可以揭示推理能力是单独提高算法问题解决的成功率,还是扩展到更实际的、与行业相关的编码任务。
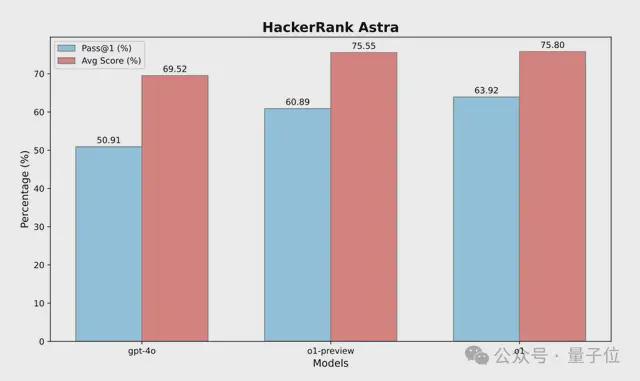
上图中的pass@1,表示首次尝试成功完成任务的概率;平均分数,代表了通过的测试用例的平均比例。
这些指标证明了o1增强的推理和适应性,使其能够有效地处理复杂的、与行业相关的软件开发任务。
这组经过验证的500个任务,修复了SWE-bench的某些问题,如正确解决方案的不正确评分、未指定的问题陈述以及过于具体的单元测试——这有助于确保基准测试准确地对模型功能进行分级。
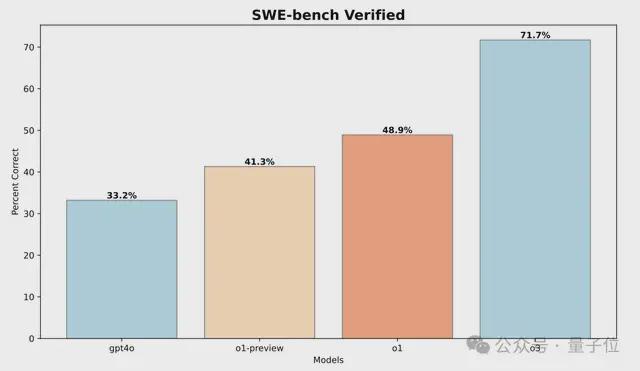
如上图所示,与GPT-4o相比,o1-preview在SWE-bench上的性能提高了 8.1%,展示了推理能力的显着进步。
值得注意的是,训练计算资源比o1多得多的o3,比o1改进了22.8%,“非常impressive”。
略显遗憾的是,OpenAI这篇新作虽然挂在了arXiv上,但更像是报告而非论文——因为整篇论文没怎么透露方法细节,光晒成绩单了。
Copyright © 2024 开云沙盘有限公司 版权所有 备案号:蜀ICP备19012180号 网站地图
