
咨询热线:
0830-2509596
0830-2509596

随着大语言模型(LLM)的快速发展,如何准确评估其能力成为人工智能研究和应用中的核心问题。从通用知识到专业推理,从编码能力到工具调用,各种基准测试(Benchmarks)为我们提供了量化模型性能的窗口。
但我们发现,每家公司在公布自己的数据时,可能用的都是不同的指标,这让我们在对比的时候十分困难,就好比每家都拿着不同的尺子。比如我们在 DeepSeek R1 的论文里面会看到这样的图:
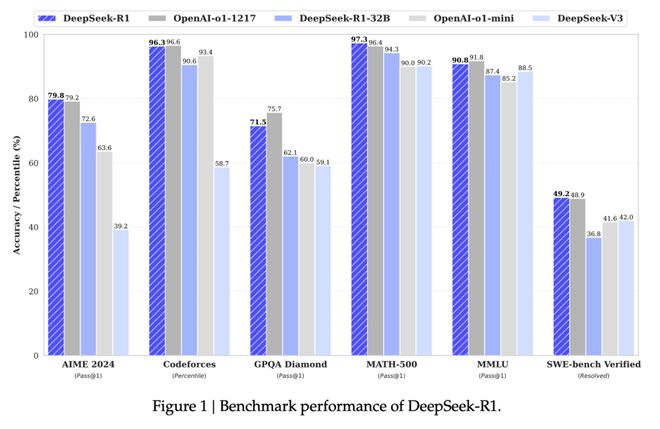
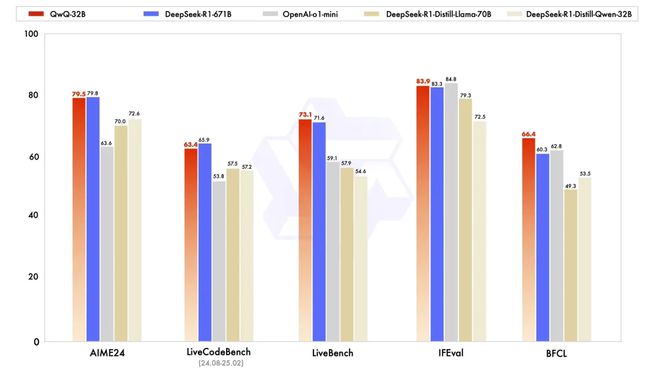
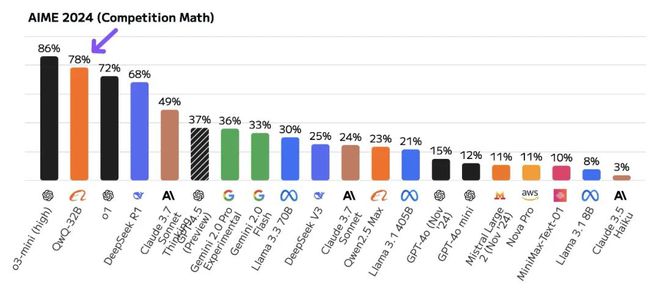
看这个数据,Qwen-QwQ -32 似乎全面超越了 DeepSeek R1,很多媒体也这宣传,那么果真如此吗?我们还得先了解这些参数才能知道。
-含义:AIME(American Invitational Mathematics Examination)是美国高中数学竞赛的一个环节,2024年版指的是当年更新的题目集。AIME题目通常涉及代数、几何、数论和组合数学,难度高于普通高中水平但低于奥林匹克级别。
-测试内容:评估模型在数学问题求解中的逻辑推理和计算能力,尤其是多步骤推理和抽象思维。
-重要性:中等偏高。数学能力是衡量模型逻辑推理和问题解决能力的重要指标。AIME2024作为较新的数据集,能避免数据污染(即模型在训练中见过类似题目),因此对测试模型的泛化能力有一定价值。但相比更难的 MATH-500 或 IMO(国际数学奥林匹克),其挑战性稍低,可能无法完全区分顶级模型。

-含义:Codeforces 是一个知名的在线竞技编程平台,定期举办编程比赛,题目涵盖算法和数据结构(如图论、动态规划、贪心算法等),并通过 Elo 评分系统衡量参赛者能力。
-测试内容:评估模型在代码生成、算法设计和问题解决中的表现。题目难度从简单到极高不等。
-重要性:高。作为动态更新的真实编程挑战平台,Codeforces 提供了一个“活的”基准,能有效检测模型在编码任务上的泛化能力和实际应用潜力。它的重要性在于题目多样性和社区验证,避免了静态数据集的过拟合问题。顶级模型(如 GPT-4)在 Codeforces 上平均 Elo 评分为 392(低于人类新手水平),显示其仍有提升空间。
-含义:GPQA(Graduate-Level Google-Proof Q&A Benchmark)Diamond 是 GPQA 数据集的高质量子集,包含 198 个由博士专家设计的多项选择题,覆盖生物学、物理Kaiyun官方入口学和化学,要求深入的专业知识和多步骤推理。这个数据集是由纽约大学、CohereAI 和 Anthropic 的研究人员联合开发的。
-测试内容:测试模型在研究生级科学问题上的推理能力和知识深度,特别强调“Google-Proof”(难以通过搜索直接解答)。
-重要性:非常高。GPQA Diamond 是目前最困难的科学问Kaiyun官方中国答基准之一,专家准确率仅 65%-74%,而顶级模型(如 OpenAI o1)达到 78%,显示其能挑战模型极限。它对评估模型在专业领域的真实理解(而非简单记忆)至关重要,尤其适用于 AGI(通用人工智能)研究。
-含义:MATH-500 是一个包含 500 个高难度数学问题的基准,源自 MATH 数据集,覆盖代数、微积分、数论等,难度接近或超过大学水平。
-测试内容:测试模型在复杂数学问题上的求解能力,强调符号推理和证明能力。
-重要性:高。数学是测试模型逻辑和抽象思维的“硬核”领域,MATH-500 的高难度使其成为区分顶级模型的重要工具。例如,链式思维(Chain-of-Thought)提示能显著提升模型表现,反映其推理深度。对追求数学强模型(如科学计算或教育应用)的开发至关重要。
-重要性:中等偏高。MMLU 是最广泛使用的通用知识基准,提供了模型整体能力的快照。顶级模型(如 Claude 3.5 Sonnet 和 GPT-4o)准确率接近 88%,但其部分题目可能已被训练数据污染,且推理要求不如 GPQA Diamond 或 MATH-500 严格,因此重要性略有下降。
-重要性:高。软件工程是 LLM 的重要应用领域,SWE-Bench Verified 的真实性和专业验证使其成为评估模型实用性的关键基准。它能揭示模型在处理复杂代码库和上下文时的表现,对工业应用(如自动化编程)意义重大。
-重要性:非常高。其动态性和多任务设计避免了数据污染,同时覆盖编码的多个方面(如调试和优化)。它能区分模型在不同编码场景中的相对优势(如 Claude-3-Opus 在测试预测上超过 GPT-4),对开发全面的代码助手至关重要。
-含义:LiveBench 是一个多领域基准,包含数学、编码、推理、语言理解、指令遵循和数据分析 6 大类 18 个任务,使用近期数据(如过去 12 个月的数学竞赛题目Kaiyun官方入口)确保无污染。
-重要性:高。LiveBench 的多样性和更新频率使其成为评估模型全面性和适应性的强大工具。当前模型最高准确率仅 65%,显示其挑战性。对开发多功能 LLM(如聊天机器人或智能代理)有重要参考价值。
-重要性:中等。指令遵循是 LLM 在实际应用(如写作助手)中的核心能力,IFEval 提供了一种客观的量化方法。但其任务较为单一,重要性不及多领域或高难度基准。
-重要性:高。随着 LLM 被集成到工具链(如自动化工作流),函数调用能力日益重要。BFCL 的多样性和实用性使其成为评估模型生态适应性的关键指标。
基于当前 LLM 发展趋势(截至 2025年3月7日),以下是重要性排序(从高到低)及理由:
1.GPQA Diamond:挑战模型极限,测试专业推理,AGI 研究核心。
2.LiveCodeBench:动态、无污染、多任务编码评估,实用性强。
- 全面性:MMLU 和 LiveBench 覆盖多领域,但可能因广度牺牲深度。
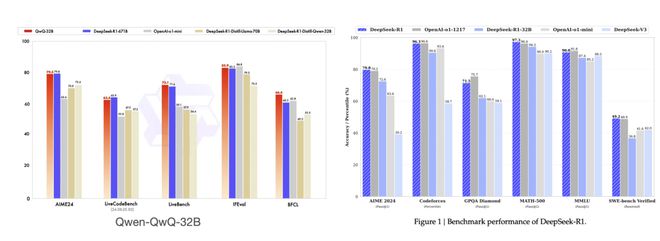
我们发现,TOP 5 的指标里面阿里只公布了一个,而 DeepSeek 几乎全公布了。对于最重要的一个参数GPQA Diamond阿里的报告里面没有,吴恩达的公司Artificial Analysis连夜做了测试:
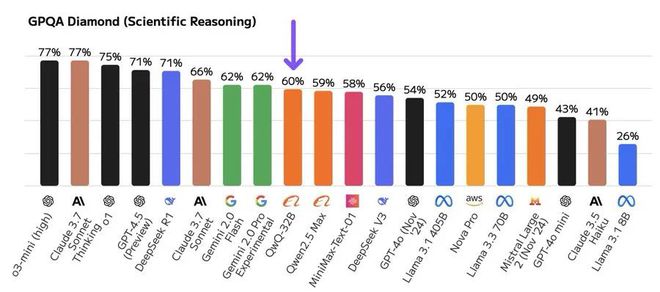
看到这里,我想你大概明白了是怎么回事。至于阿里的 Qwen-QwQ-32B 是否真的能以小博大,超越比自己大 20 倍参数的 DeepSeek R1。很明显不可能,充其量只是在某些指标上超越。但完整的结论只有等到双方的对比指标都一致才能进行判断,吴恩达的公司Artificial Analysis正在进行测试,相信谜底很快就能揭晓了。
Copyright © 2024 开云沙盘有限公司 版权所有 备案号:蜀ICP备19012180号 网站地图
