
咨询热线:
0830-2509596
0830-2509596

过去几年,大语言模型(LLM)的Kaiyun全站网页浪潮席卷学术界与产业界。在科研场景中,它们正从 “工具” 演变为 “合作者”,科学大语言模型(Sci-LLMs)的进展尤为瞩目。
然而,科学数据的多模态、跨尺度、强领域语义与不确定性,以及科学知识本身的层次化结构,对 Sci开云网站-LLMs 提出了远超通用领域的新要求。当前的研究仍处于碎片化状态,缺乏对全学科领域的科学数据与模型演进路径的系统性梳理。一个系统性的梳理与前瞻性设计已成为整个领域的迫切需求。

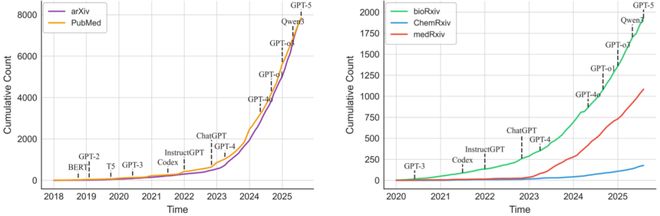
近年来,人工智能在科学探索(AI for Science)领域的应用呈现爆发式增长,科学大语言模型正以前所未有的深度和广度变革着知识的表示、整合与应用方式,在物理、化学、材料、生命科学、天文、地球科学等多个自然科学领域展现出惊人的潜力,重新定义着科学研究的方式。如下图,综述简要展示了在主要预印本平台上,涉及 “language model” 及其与科学领域结合(联合检索学科关键词)的论文发表趋势。左图显示 arXiv 与 PubMed 上的快速增长,右图则呈现 bioRxiv、medRxiv 和 ChemRxiv 的加速态势,体现出跨学科兴趣的不断升温。
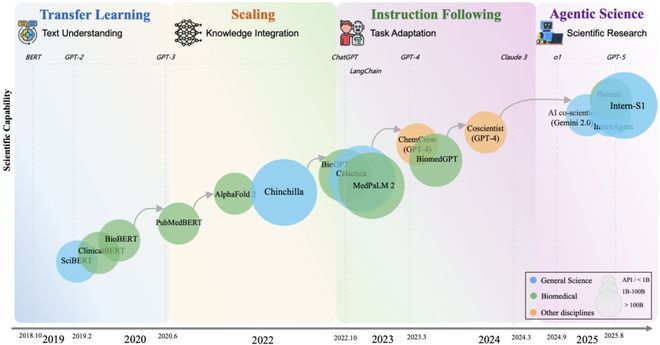
综述首先指出,2018–2025 年,数据驱动的 Sci-LLMs 已经历四次关键范式转移,其能力边界得到不断拓展,逐步迈向更高阶的科研应用阶段。
特点:通过急剧扩大的参数和数据规模,模型展现出跨学科知识整合与专业推理能力。例如,MedPaLM-2 在美国医师执照考试(USMLE)问题上达到了与持证医师相当的专家级水平。然而,这一阶段也展示出科学领域的独特挑战:高质量科学文本语料远小于通用语料,限制了 Sci-LLMs 的大规模扩展。
代表:Coscientist、Biomni、InternAgent 等
特点:除了进一步规模化来提供更加强大的科学基座(如Intern-S1),由 Sci-LLMs 构成的系统开始具备科学智能体(Agent)的雏形。AI 不再仅仅 “理解科学”,而是能自主规划实验、撰写论文、迭代科研流程。这也对新型科学数据以及科学发现性能评估提出了新的要求。
这篇综述不仅覆盖了六大科学领域(物理、化学、材料科学、生命科学、天文学、地球科学),还揭示了它们在 数据尺度上的层层递进。
这种从微观到宏观的尺度演进,正是 Sci-LLMs 预训练数据设计的逻辑:模型需要同时理解分子动力学的精细结构,也要能把握天体演化和气候变化的宏大趋势。
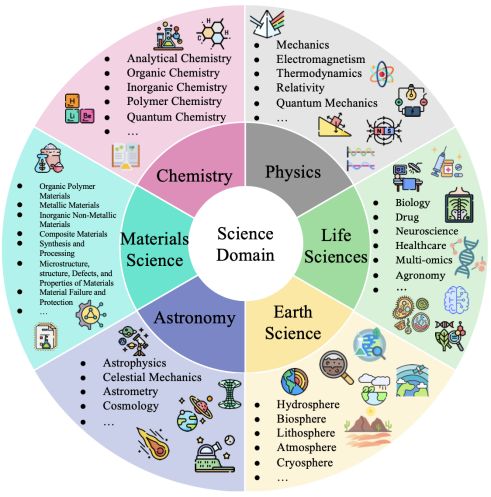
图 3:综述所涵盖的六大科学领域(物理、化学、材料科学、生命科学、地球科学、天文学)及各领域中的代表性子方向。
通才型 Sci-LLMs 致力于构建跨学科的知识底座,典型代表是 Intern-S1。它通过在海量、跨学科的科学语料(涵盖论文、教科书、百科、习题等)上进行大规模预训练,具备广博而系统的科学知识储备。与此相对,专才型 Sci-LLMs 则更像是针对单一学科定制的 “手术刀”,依靠在特定领域(如高能物理、化学、生命科学等)的专业数据集上进行深度训练,成为该学科的专家,例如专注高能物理的 Xiwu,以及面向化学的 ChemLLM。
与两者相比,Intern-S1 的独特优势在于通专融合:它既继承了通才模型的跨学科广度,能够在复杂问题中调用多领域知识;又通过针对重点学科的优化实现了专才模型的深度,具备解决专业领域难题的能力。凭借这一双重特性,Intern-S1 不仅能作为科学研究的通用助手,还能够在特定学科场景下展现接近专家级的推理与回答水平。
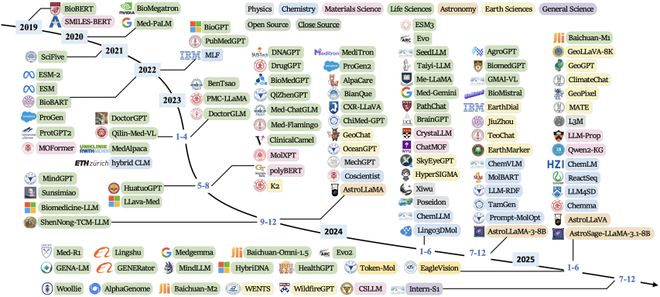
图 4:按六大科学领域分类的代表性 Sci-LLMs 时间概览(2019 年至 2025 年中)。
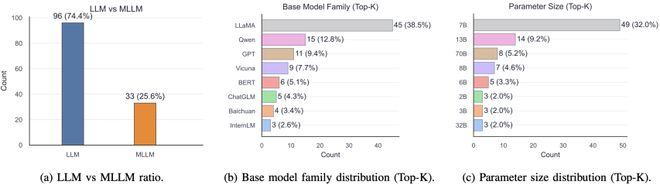
综述的统计分析指出:当前约四分之三的科学大语言模型是纯文本 LLM ,而多模态 LLM 仅占四分之一。这一方面反映了科学知识的主要载体 —— 学术论文和教科书等 —— 仍以文本为主;另一方面也暴露了高质量、细粒度的多模态监督数据的稀缺性。这种对文本的过度依赖造成了一个核心困境:模型学习到的更多是对科学的 “描述”,而非从第一性原理和实验证据中习得的科学研究本身。为了弥合这一鸿沟,未来的趋势必然是向多模态生态系统演进,尤其是在天文学、气候科学等高度依赖异构信号融合的领域,能够综合处理图像、光谱、时间序列和文本等多模态数据将是 Sci-LLMs 发展的关键 。
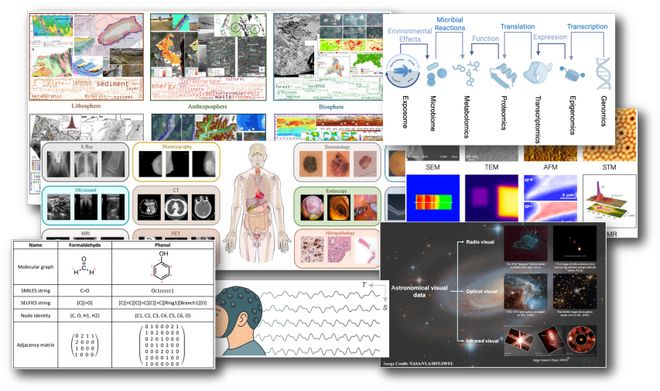
综述指出,构建强大的 Sci-LLMs 必须首先理解科学数据与知识的内在结构。为此,论文提出了两大数据分级框架:
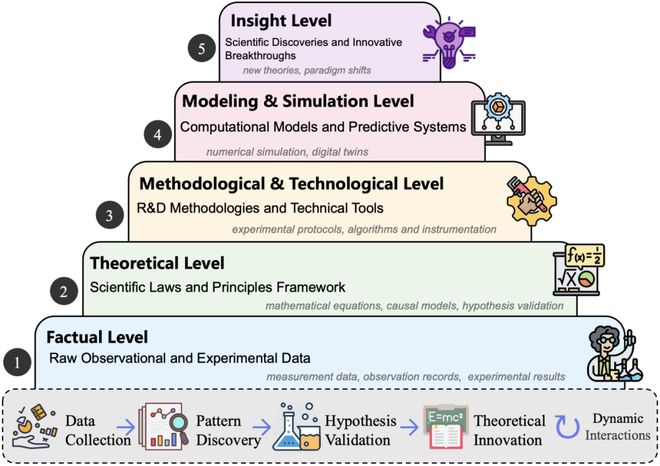
科学知识的层次化模型,该模型认为科学知识并非扁平的信息集合,而是一个由五个层次构成的复杂系统,从底层的事实层(Factual Level)、理论层(Theoretical Level),到方法技术层(Methodological & Technological Level)、建模仿真层(Modeling & Simulation Level),最终达到顶端的洞见层(Insight Level)。只有让 AI 模型理解并能在这五个层级之间穿梭,才能实现从具体到抽象、从现象到本质的科学推理,而不仅仅是事实的复述。
综述强调,高质量的数据是 Sci-LLMs 成功的关键,并提出了评估科学数据 “AI-ready” 质量的四要素,与当前数据生态存在的不足,以及其背后的系统性痛点。
可追溯性危机:大量科学数据集缺乏对其来源、版本和预处理流程的完整记录,导致 AI 模型的结论难以复现和验证,也削弱了 AI 生成假设的可信度;
科学数据延迟:从一项科研成果诞生到其数据被纳入模型训练语料库,存在数月甚至数年的滞后。这使得模型知识迅速过时,尤其在生物医学等快速发展的领域,模型可能无法回答关于最新发现的问题;
AI-readiness 不足:绝大多数科学数据并非为 AI “开箱即用” 。不规范的数据格式、缺失的元数据和异构的结构,使得研究者需花费大量精力进行数据清洗和预处理,这直接限制了 Sci-LLMs 开发的效率和规模以及高级科学智能的上限。
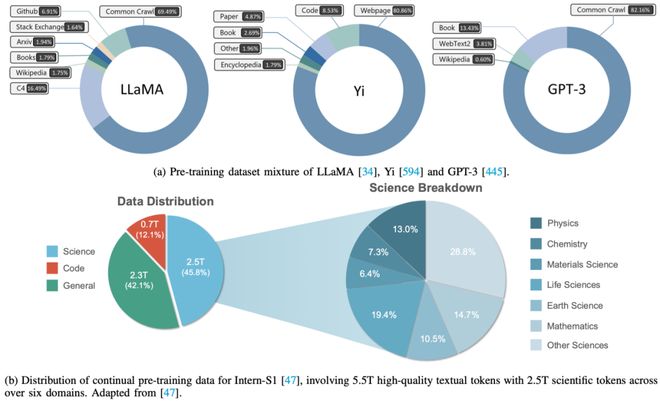
预训练数据是科学大语言模型(Sci-LLMs)的核心基础,它决定了模型能否在复杂科学场景中具备理解、推理和生成的能力。本章首先回顾了当前模型在预训练数据上的总体分布:例如 Yi 模型结合了网页、代码、论文和问答等多源数据,而 LLaMA 的预训练语料约 1.4TB,涵盖 CommonCrawl、GitHub、Wikipedia 与学术资源(见图 8a)。
相比之下,Intern-S1 在总语料中专门划分出约 2.5 万亿 tokens(占比 45.8%)用于科学领域,覆盖物理、化学、材料科学、生命科学、天文学和地球科学六大板块,为后续的领域拆解奠定了基础。作者强调,科学语料的广度与真实性直接影响模型能否在科学场景中进行理解、推理与生成。
在回顾整体的语料构成之后,综述进一步从学科尺度深入分析了科学大语言模型预训练数据的特点与挑战。
物理学的数据多来自理想化仿真与理论推导,如偏微分方程与动力学模拟,但与真实观测之间存在显著差距,因此亟需解决 simulation-to-observation gap,使模型既能学习物理定律,又能适应实验噪声和仪器特性。
化学预训练以分子结构和性质数据为核心,包括 SMILES 表示、量子化学计算结果与反应数据库等,虽然结构化程度高,但实验标注成本昂贵,限制了语料规模,因此提升分子表征的多样性与覆盖度是关键。
材料科学主要依赖大型材料数据库(如 Materials Project、NOMAD、OQMD),涵盖晶体结构、能带、力学与热学性质,但由于元数据与计算条件不一致,跨数据库融合存在障碍,未来需要标准化与跨模态的统一表示。
生命科学覆盖基因、蛋白质序列、多组学数据、医学影像与电子病历等,数据量庞大却因隐私与伦理问题常常不完整或滞后,现有方法多通过去标识化、合成数据与多模态整合来缓解。
天文学的科学数据包括光谱、射电观测、星系影像与宇宙学模拟,然而不同仪器在分辨率、带宽与校准上的差异,使得跨模态和跨设备对齐成为挑战。
地球科学的数据则最为稀缺,主要依赖论文与教材 PDF 的解析,以及有限的遥感影像和气候变量场,但其高度异质性导致文本解析和图像对齐的代价很高,未来的发展趋势是通过多源融合与自动标注来扩展规模。

图 9:预训练数据集的词云图。图中展示了模态(左)和类型(右)的相对分布,词语大小与出现频率成正比。
在完成大规模预训练后,科学大语言模型还需要进一步 后训练(post-training),以便从 “具备科学常识” 走向 “能够真正解决科学问题”。与预训练强调 广覆盖与大规模 不同,后训练更关注 高质量、任务导向与学科特色 的数据。本章从多个科学领域系统介绍了后训练数据的构建现状与难点,并指出当前后训练数据呈现四大趋势:
指令化语料占主导:将结构化知识库、教科书习题等转化为指令 - 回复对。
多模态数据集日益重要:在医学、遥感等领域,视觉问答(VQA)数据集已成为主流。
向显式推理监督演进:带有思维链(CoT)的推理过程数据开始出现,以提升模型的可解释性。
数据合成的自动化趋势:以强大的 LLM(如 GPT-4)为数据处理工具,从文献和数据库中自动生成海量指令数据,以弥补人工标注的不足。
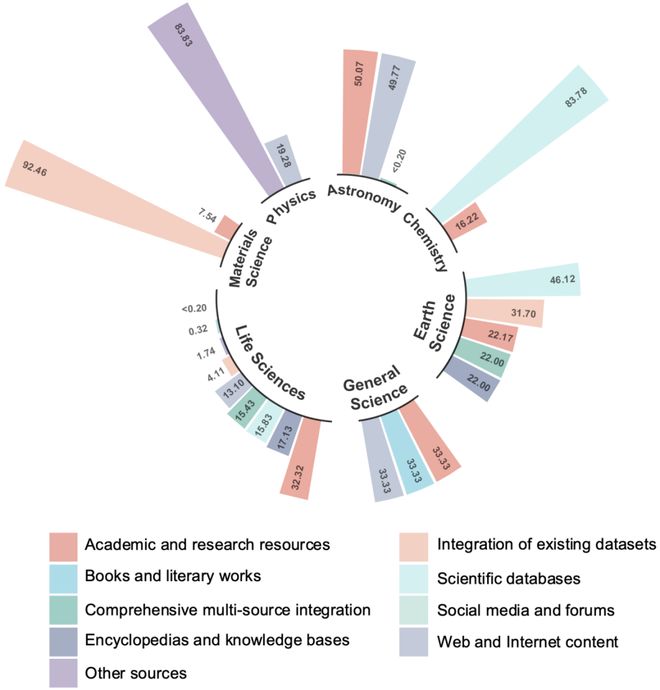

图 11:后训练数据集的词云图。图中展示了模态(左)和类型(右)的相对分布,词语大小与出现频率成正比。
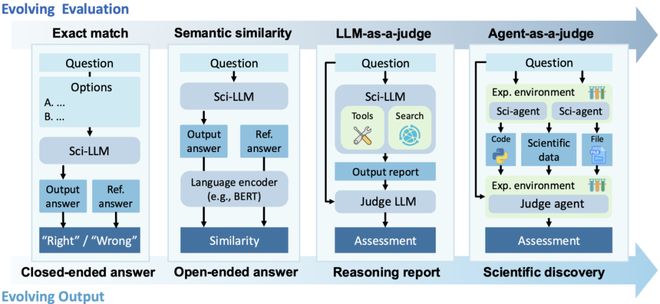
测评数据是连接 预训练 / 后训练 与 真实科研应用 的关键环节。与通用 LLM 测评(如 MMLU、MMMU)不同,Sci-LLMs 的测评更强调:
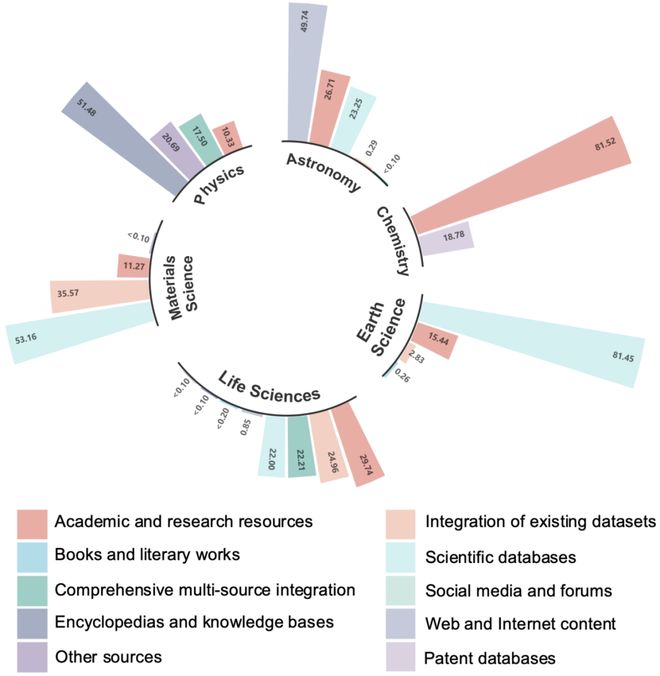

图 13:评测数据集的词云图。图中展示了模态(左)和类型(右)的相对分布,词语大小与出现频率成正比。
综述指出,Sci-LLMs 的评测正经历从 “静态考试型测试” 到 “动态、过程导向型测评” 的转变。早期评测多采用 MMLU 、ScienceQA 等 “考试” 型基准,但最新研究发现,顶尖模型在这些基准上取得高分,但在真正考验前沿、跨领域科学推理的测试(如 HLE、SFE)上表现会急剧下降。这催生了评测范式的三大升级:
从通用指标到领域定制:除了准确率,评测开始引入化学有效性、物理学公式匹配度等专业指标;
从静态问答到动态流程:新一代评测基准如 ScienceAgentBench ,要求模型完成文献检索、实验设计、代码执行等完整的科研工作流,评估其过程的正确性;
从人工评判到智能体评判:引入 “Agent-as-a-Judge” 范式,利用一个或多个 AI 智能体来评估目标模型的开放式回答、假设新颖性等难以量化的能力,实现更高效、可解释的评估。
尽管近年来已经出现了面向不同学科的评测基准,但整体来看,科学测评数据依然存在明显不足。这些不足不仅体现在学科覆盖的不均衡上,也体现在模态、真实性与动态性等维度的缺失,使得现有评估体系难以全面衡量模型在真实科研场景中的表现。
针对上述问题,研究者们也提出了新的发展方向,尝试让测评体系更接近科学实践的真实需求。趋势既包括评测范式的转变,也涵盖多模态与跨学科的拓展,最终目标是建立起动态而全面的科学智能评估框架。
过程导向测评:从 “对 / 错” 答案转向检验模型的推理链、实验解释、科学方法论;
跨学科评测:推动建立涵盖物理、化学、材料、生命、天文、地球科学等多学科的统一基准;
闭环评测:发展 “自动化科学代理人” 评估框架,让模型在实验仿真、假设检验、数据分析中被动态测试。
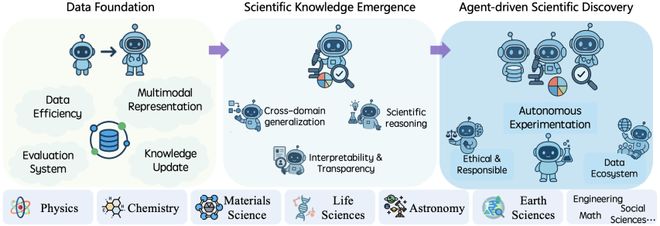
图 15:从数据基础设施到智能体辅助的科学发现:科学 AI 的三阶段演进。
综述最后展望了 Sci-LLMs 的下一代形态 —— 科学智能体(Scientific Agent)。不同于被动回答问题的模型,科学智能体是能够被赋予高级目标(如 “为某疾病寻找候选药物”)后,自主进行任务分解、规划、工具调用、虚拟实验和结果分析的自治系统。
综述指出,实现这一目标的核心在于构建一个闭环的 “智能体 - 数据” 生态系统。在这个系统中,智能体通过与外部工具(数据库、模拟器、甚至自动化实验室)交互来主动获取和生成新的实验数据;这些 “AI-ready” 的数据再反哺数据生态,用于迭代和优化智能体自身,形成一个能够自我进化的良性循环。综述详细探讨了实现这一闭环所需的关键技术,包括多智能体协作、工具使用和自进化机制。
建立了统一的科学大模型数据理论框架,为分析科学数据和知识的复杂性提供了全新视角。
提供了最全面的数据、模型和测评体系分析全景图,系统性梳理了超过 600 个数据集与模型,揭示了各学科的现状与挑战。
指出了数据生态的结构性瓶颈,并为构建高质量、可信的 AI-ready 科学数据提出了前瞻性议程。
描绘了迈向自主科学发现的路线图,倡导构建智能体与数据生态之间的闭环反馈系统。
正如文中所指出的,Sci-LLMs 正从单纯的 “知识模型” 向 “推理引擎” 和 “科研伙伴” 演进,解决好其在数据基础和智能体层面的核心挑战,将是未来研究的重中之重。
Copyright © 2024 开云沙盘有限公司 版权所有 备案号:蜀ICP备19012180号 网站地图
