
咨询热线:
0830-2509596
0830-2509596

Gemma 2拥有9B和27B参数规模,相比第一代模型在推理效率和安全性上有显著提升。
27B的Gemma 2在同等规模模型中表现最佳,甚至可与体积两倍的模型竞争。
优化在各种硬件上高速运行,从高端桌面、游戏笔记本和云端设置上都能实现高效运行。
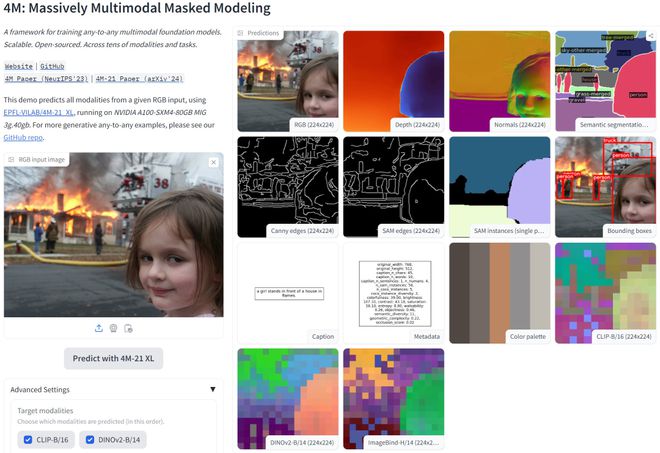
苹果和EPFL联合开源的多模态模型训练框架,业界Kaiyun官方中国良心,含金量巨高!支持数十种模态和任务,读图能力支持表面法线、深度图、图片分割、物体检测、图片描述。画图能力支持线框补图、画深度图和表面法线、基于深度图和区域修改图片。支持微调来适配新类型的任务
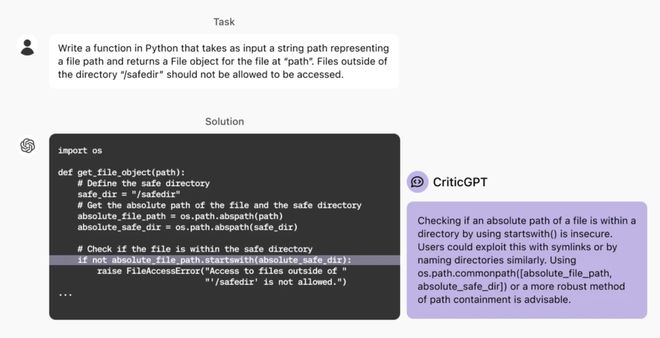
CriticGPT,一种基于GPT-4训练优化的模型,专门用于来发现ChatGPT中的代码错误。
通过与人类合作CriticGPT能够显著减少模型幻觉,同时保持高效的错误检测能力。
当前的LLM模型如ChatGPT等,在生成复杂代码时,即使是经验丰富的专家也难以可靠地评估其输出的质量和正确性。CriticGPT通过训练模型生成自然语言评论,帮助人类更准确地评估代码,从而弥补了人类评估的局限性。
研究发现,在CriticGPT的帮助下,人们审查ChatGPT代码的表现比没有帮助时高出60%。
1.9B包含:Index-1.9B base : 基座模型,具有 19亿 非词嵌入参数量,在2.8T 中英文为主的语料上预训练,多个评测基准上与同级别模型比处于领先Index-1.9B pure : 基座模型的对照组,与base具有相同的参数和训练策略,不同之处在于严格过滤了该版本语料中所有指令相关的数据,以此来验证指令对benchmark的影响Index-1.9B chat : 基于index-1.9B base通过SFT和DPO对齐后的对话模型,由于预训练中引入了较多互联网社区语料,聊天的趣味性明显更强Index-1.9B character : 在SFT和DPO的基础上引入了RAG来实现fewshots角色扮演定制
DeepSeek-Coder-V2:代码和数学能力超越GPT-4的开源模型
开放论文,模型和代码,支持 236B 和 16B,支持微调并开放 API 服务

视频生成模型正在以惊人的速度发展,但许多当前系统只能生成无声输出。让生成的电影栩栩如生的下一个重要步骤之一是为这些无声视频创建配乐。
谷歌分享了视频转音频 (V2A) 技术的进展,该技术使同步视听生成成为可能。V2A 将视频像素与自然语言文本提示相结合,为屏幕上的动作生成丰富的音景。

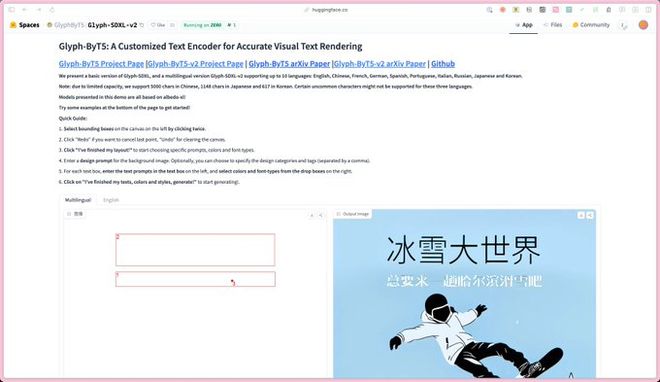
谷歌这个项目可根据提示词创造各种字母形式,然后用它来书写各种内容 非常适合制作标题或封面艺术!


还搭配了一个使用这个文本编码器的 SDXL 模型,可以直接生成中文海报和内容。
创建了一个高质量的多语言字形文本和图形设计数据集,包含超过100万个字形文本对和1000万个图形设计图像文本对,覆盖另外九种语言;
构建了一个多语言视觉段落基准数据集,包括1000个提示,每种语言100个,用于评估多语言视觉拼写准确性;

可以在这个 huggingface 空间里面体验,支持通过画框进行自定义排版。
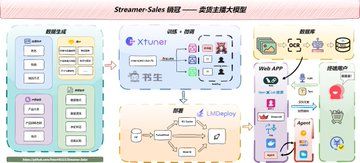
它能根据商品特点自动生成吸引用户的解说文案,支持将语音输入转换为文字,便于主播在直播过程中与观众互动。
同时还能生成带有情感的语音输出,使解说更加生动自然。还能一键生成数字人。
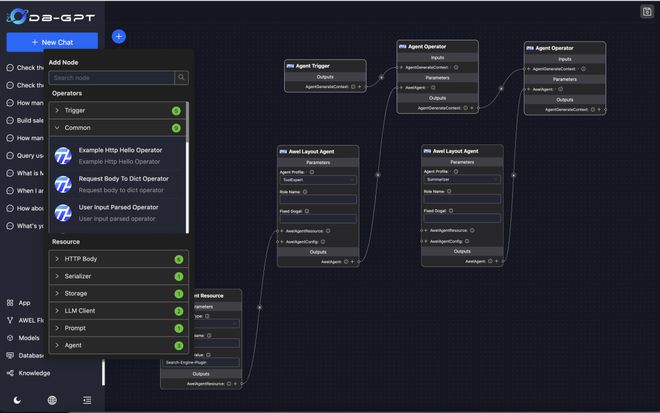
构建生产级别的 AI Native Agent 应用!支持图可视化和详细示例代码!
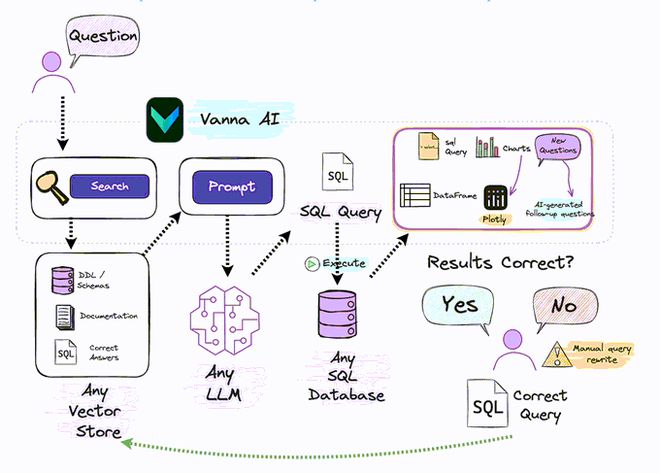
LlamaIndex 数据处理、RAG 、Agentic RAG PPT 和代码

输入文档、表格、视频、音频、网页等Kaiyun官方中国数据,OmniParse可以把数据清洗成结构化的数据,然后可以用于微调和RAG。

你可以用它来创建私人教练、会议助手、儿童故事讲述玩具、客服机器人等 AI 语音助手。
Copyright © 2024 开云沙盘有限公司 版权所有 备案号:蜀ICP备19012180号 网站地图
